







[sc name=”ad_1″]
A golang utility to spider through a website searching for additional links with support for JavaScript rendering.
Install
go get -u github.com/iamstoxe/urlgrabFeatures
- Customizable Parallelism
- Ability to Render JavaScript (including Single Page Applications such as Angular and React)
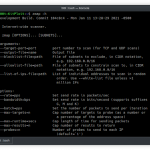
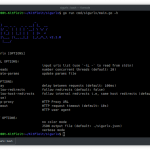
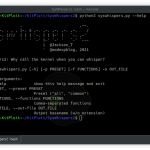
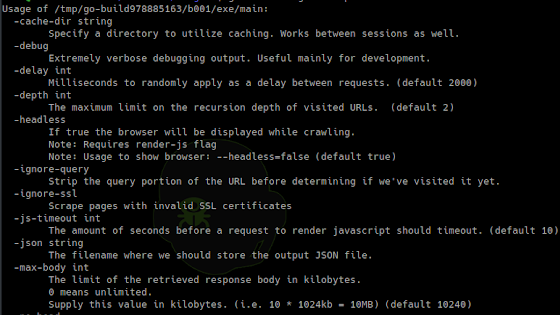
Usage of urlgrab:
-cache-dir string
Specify a directory to utilize caching. Works between sessions as well.
-debug
Extremely verbose debugging output. Useful mainly for development.
-delay int
Milliseconds to randomly apply as a delay between requests. (default 2000)
-depth int
The maximum limit on the recursion depth of visited URLs. (default 2)
-headless
If true the browser will be displayed while crawling.
Note: Requires render-js flag
Note: Usage to show browser: --headless=false (default true)
-ignore-query
Strip the query portion of the URL before determining if we've visited it yet.
-ignore-ssl
Scrape pages with invalid SSL certificates
-js-timeout int
The amount of seconds before a request to render javascript should timeout. (default 10)
-json string
The filename where we should store the output JSON file.
-max-body int
The limit of the retrieved response body in kilobytes.
0 means unlimited.
Supply this value in kilobytes. (i.e. 10 * 1024kb = 10MB) (default 10240)
-no-head
Do not send HEAD requests prior to GET for pre-validation.
-output-all string
The directory where we should store the output files.
-proxy string
The SOCKS5 proxy to utilize (format: socks5://127.0.0.1:8080 OR http://127.0.0.1:8080).
Supply multiple proxies by separating them with a comma.
-random-agent
Utilize a random user agent string.
-render-js
Determines if we utilize a headless chrome instance to render javascript.
-root-domain string
The root domain we should match links against.
If not specified it will default to the host of --url.
Example: --root-domain google.com
-threads int
The number of threads to utilize. (default 5)
-timeout int
The amount of seconds before a request should timeout. (default 10)
-url string
The URL where we should start crawling.
-urls string
A file path that contains a list of urls to supply as starting urls.
Requires --root-domain flag.
-user-agent string
A user agent such as (Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0).
-verbose
Verbose outputAuthor
Devin Stokes
- Twitter: @DevinStokes
- Github: @IAmStoxe
[sc name=”ad-in-article”]

Add Comment