







[sc name=”ad_1″]
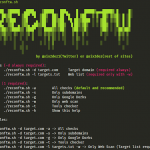
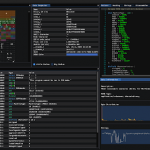
Security Tool for Reconnaissance and Information Gathering on a website. (python 2.x & 3.x)
This script use “WafW00f” to detect the WAF in the first step (https://github.com/EnableSecurity/wafw00f)
This script use “Sublist3r” to scan subdomains (https://github.com/aboul3la/Sublist3r)
This script use “waybacktool” to check in waybackmachine (https://github.com/Rhynorater/waybacktool)
Features
- URL fuzzing and dir/file detection
- Test backup/old file on all the files found (index.php.bak, index.php~ …)
- Check header information
- Check DNS information
- Check whois information
- User-agent random or personal
- Extract files
- Keep a trace of the scan
- Check @mail in the website and check if @mails leaked
- CMS detection + version and vulns
- Subdomain Checker
- Backup system (if the script stopped, it take again in same place)
- WAF detection
- Add personal prefix
- Auto update script
- Auto or personal output of scan (scan.txt)
- Check Github
- Recursif dir/file
- Scan with an authenfication cookie
- Option –profil to pass profil page during the scan
- HTML report
- Work it with py2 and py3
- Add option rate-limit if app is unstable (–timesleep)
- Check in waybackmachine
- Response error to WAF
- Check if DataBase firebaseio existe and accessible
- Automatic threads depending response to website (and reconfig if WAF detected too many times). Max: 30
- Search S3 buckets in source code page
- Testing bypass of waf if detected
TODO
P1 is the most important
- Dockerfile [P1]
- JS parsing and analysis [P1]
- Analyse html code webpage [P1]
- On-the-fly writing report [P1]
- Check HTTP headers/ssl security [P2]
- Fuzzing amazonaws S3 Buckets [P2]
- Anonymous routing through some proxy (http/s proxy list) [P2]
- Check pastebin [P2]
- Access token [P2]
- Check source code and verify leak or sentsitive data in the Github [P2]
- Check phpmyadmin version [P3]
- Scan API endpoints/informations leaks [ASAP]
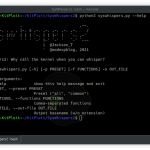
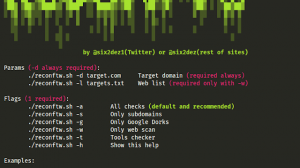
Usage
pip(3) install -r requirements.txt
If problem with pip3:
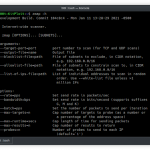
sudo python3 -m pip install -r requirements.txtusage: hawkscan.py [-h] [-u URL] [-w WORDLIST] [-s SUBDOMAINS] [-t THREAD] [-a USER_AGENT] [--redirect] [-r] [-p PREFIX] [-o OUTPUT] [--cookie COOKIE_] [--exclude EXCLUDE] [--timesleep TS] [--auto]optional arguments:
-h, --help show this help message and exit
-u URL URL to scan [required]
-w WORDLIST Wordlist used for URL Fuzzing. Default: dico.txt
-s SUBDOMAINS subdomain tester
-t THREAD Number of threads to use for URL Fuzzing. Default: 20
-a USER_AGENT choice user-agent
--redirect For scan with redirect response like 301,302
-p PREFIX add prefix in wordlist to scan
-o OUTPUT output to site_scan.txt (default in website directory)
-b Add a backup file scan like 'exemple.com/ex.php.bak...' but longer
-r recursive dir/files
--cookie COOKIE Scan with an authentification cookie
--exclude EXCLUDE To define a page type to exclude during scan
--timesleep TS To define a timesleep/rate-limit if app is unstable during scan
--auto Automatic threads depending response to website. Max: 20
--update For automatic updateExemples
//Basic
python hawkscan.py -u https://www.exemple.com -w dico_extra.txt
//With redirect
python hawkscan.py -u https://www.exemple.com -w dico_extra.txt -t 5 --redirect
//With backup files scan
python hawkscan.py -u https://www.exemple.com -w dico_extra.txt -t 5 -b
//With an exclude page
python hawkscan.py -u https://www.exemple.com -w dico_extra.txt -t 5 --exclude https://www.exemple.com/profile.php?id=1
//With an exclude response code
python hawkscan.py -u https://www.exemple.com -w dico_extra.txt -t 5 --exclude 403
Thanks
Layno (https://github.com/Clayno/)
Sanguinarius (https://twitter.com/sanguinarius_Bt)
Cyber_Ph4ntoM (https://twitter.com/__PH4NTOM__)
[sc name=”ad-in-article”]

Add Comment