







[sc name=”ad_1″]
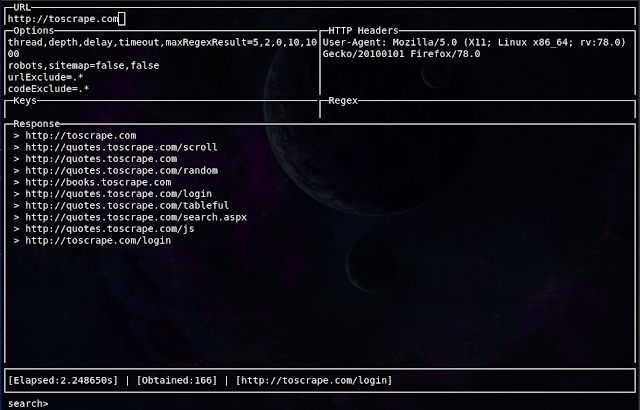
Evine is a simple, fast, and interactive web crawler and web scraper written in Golang. Evine is useful for a wide range of purposes such as metadata and data extraction, data mining, reconnaissance and testing.

Follow the project on Twitter.
Install
From Binary
Pre-build binary releases are also available.
From source
go get github.com/saeeddhqan/evine
"$GOPATH/bin/evine" -hFrom GitHub
git clone https://github.com/saeeddhqan/evine.git
cd evine
go build .
mv evine /usr/local/bin
evine --helpNote: golang 1.13.x required.
Commands & Usage
| Keybinding | Description |
|---|---|
| Enter | Run crawler (from URL view) |
| Enter | Display response (from Keys and Regex views) |
| Tab | Next view |
| Ctrl+Space | Run crawler |
| Ctrl+S | Save response |
| Ctrl+Z | Quit |
| Ctrl+R | Restore to default values (from Options and Headers views) |
| Ctrl+Q | Close response save view (from Save view) |
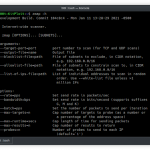
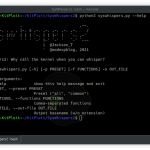
evine -hIt will displays help for the tool:
| flag | Description | Example |
|---|---|---|
| -url | URL to crawl for | evine -url toscrape.com |
| -url-exclude string | Exclude URLs maching with this regex (default “.*”) | evine -url-exclude ?id= |
| -domain-exclude string | Exclude in-scope domains to crawl. Separate with comma. default=root domain | evine -domain-exclude host1.tld,host2.tld |
| -code-exclude string | Exclude HTTP status code with these codes. Separate whit ‘|’ (default “.*”) | evine -code-exclude 200,201 |
| -delay int | Sleep between each request(Millisecond) | evine -delay 300 |
| -depth | Scraper depth search level (default 1) | evine -depth 2 |
| -thread int | The number of concurrent goroutines for resolving (default 5) | evine -thread 10 |
| -header | HTTP Header for each request(It should to separated fields by n). | evine -header KEY: VALUEnKEY1: VALUE1 |
| -proxy string | Proxy by scheme://ip:port | evine -proxy http://1.1.1.1:8080 |
| -scheme string | Set the scheme for the requests (default “https”) | evine -scheme http |
| -timeout int | Seconds to wait before timing out (default 10) | evine -timeout 15 |
| -keys string | What do you want? write here(email,url,query_urls,all_urls,phone,media,css,script,cdn,comment,dns,network,all, or a file extension) | evine -keys urls,pdf,txt |
| -regex string | Search the Regular Expression on the page contents | evine -regex ‘User.+’ |
| -max-regex int | Max result of regex search for regex field (default 1000) | evine -max-regex -1 |
| -robots | Scrape robots.txt for URLs and using them as seeds | evine -robots |
| -sitemap | Scrape sitemap.xml for URLs and using them as seeds | evine -sitemap |
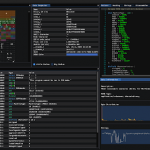
VIEWS
- URL: In this view, you should enter the URL string.
- Options: This view is for setting options.
- Headers: This view is for setting the HTTP Headers.
- Keys: This view is used after the crawling web. It will be used to extract the data(docs, URLs, etc) from the web pages that have been crawled.
- Regex: This view is useful to search the Regexes in web pages that have been crawled. Write your Regex in this view and press Enter.
- Response: All of the results write in this view
- Search: This view is used to search the Regexes in the Response content.
TODO
- Archive crawler as seeds
- JSON output
Bugs or Suggestions
Bugs or suggestions? Create an issue.
evine is heavily inspired by wuzz.
[sc name=”ad-in-article”]

Add Comment