








[sc name=”ad_1″]
A multi-threaded AWS inventory collection tool.
The creators of this tool have a recurring need to be able to efficiently collect a large amount of AWS resource attributes and metadata to help clients understand their cloud security posture.
There are a handful of tools (e.g. AWS Config, CloudMapper, CloudSploit, Prowler) that do some form of resource collection to support other functions. But we found we needed broader coverage and more details at a per-service level. We also needed a consistent and structured format that allowed for integration with our other systems and tooling.
Enter AWS Recon, multi-threaded AWS inventory collection tool written in plain Ruby. Though most AWS tooling tends to be dominated by Python, the Ruby SDK is quite mature and capable. The maintainers of the Ruby SDK have done a fantastic job making it easy to handle automatic retries, paging of large responses, and threading huge numbers of requests.
Project Goals
- More complete resource coverage than available tools (especially for ECS & EKS)
- More granular resource detail, including nested related resources in the output
- Flexible output (console, JSON lines, plain JSON, file, standard out)
- Efficient (multi-threaded, rate limited, automatic retries, and automatic result paging)
- Easy to maintain and extend
Setup
Requirements
Ruby 2.5.x or 2.6.x (developed and tested with 2.6.5)
Installation
Install the gem:
$ gem install aws_recon
Fetching aws_recon-0.2.2.gem
Fetching aws-sdk-resources-3.76.0.gem
Fetching aws-sdk-3.0.1.gem
Fetching parallel-1.19.2.gem
...
Successfully installed aws-sdk-3.0.1
Successfully installed parallel-1.19.2
Successfully installed aws_recon-0.2.2Or add it to your Gemfile using bundle:
$ bundle add aws_recon
Fetching gem metadata from https://rubygems.org/
Resolving dependencies...
...
Using aws-sdk 3.0.1
Using parallel 1.19.2
Using aws_recon 0.2.2Usage
AWS Recon will leverage any AWS credentials currently available to the environment it runs in. If you are collecting from multiple accounts, you may want to leverage something like aws-vault to manage different credentials.
$ aws-vault exec profile -- aws_reconPlain environment variables will work fine too.
$ AWS_PROFILE=<profile> aws_reconYou may want to use the -v or --verbose flag initially to see status and activity while collection is running.
In verbose mode, the console output will show:
<thread>.<region>.<service>.<operation>The t prefix indicates which thread a particular request is running under. Region, service, and operation indicate which request operation is currently in progress and where.
$ aws_recon -v
t0.global.EC2.describe_account_attributes
t2.global.S3.list_buckets
t3.global.Support.describe_trusted_advisor_checks
t2.global.S3.list_buckets.acl
t5.ap-southeast-1.WorkSpaces.describe_workspaces
t6.ap-northeast-1.Lightsail.get_instances
...
t2.us-west-2.WorkSpaces.describe_workspaces
t1.us-east-2.Lightsail.get_instances
t4.ap-southeast-1.Firehose.list_delivery_streams
t7.ap-southeast-1.Lightsail.get_instances
t0.ap-south-1.Lightsail.get_instances
t1.us-east-2.Lightsail.get_load_balancers
t7.ap-southeast-2.WorkSpaces.describe_workspaces
t2.eu-west-3.SageMaker.list_notebook_instances
t3.eu-west-2.SageMaker.list_notebook_instances
Finished in 46 seconds. Saving resources to output.json.
Example command line options
$ AWS_PROFILE=<profile> aws_recon -s S3,EC2 -r global,us-east-1,us-east-2$ AWS_PROFILE=<profile> aws_recon --services S3,EC2 --regions global,us-east-1,us-east-2Errors
An exception will be raised on AccessDeniedException errors. This typically means your user/role doesn’t have the necessary permissions to get/list/describe for that service. These exceptions are raised so troubleshooting access issues is easier.
Traceback (most recent call last):
arn:aws:sts::1234567890:assumed-role/role/9876543210 is not authorized to perform: codepipeline:GetPipeline on resource: arn:aws:codepipeline:us-west-2:876543210123:pipeline (Aws::CodePipeline::Errors::AccessDeniedException)The exact API operation that triggered the exception is indicated on the last line of the stack trace. If you can’t resolve the necessary access, you should exclude those services with -x or --not-services so the collection can continue.
Threads
AWS Recon uses multiple threads to try to overcome some of the I/O challenges of performing many API calls to endpoints all over the world.
For global services like IAM, Shield, and Support, requests are not multi-threaded. The S3 module is multi-threaded since each bucket requires several additional calls to collect complete metadata.
For regional services, a thread (up to the thread limit) is spawned for each service in a region. By default, up to 8 threads will be used. If your account has resources spread across many regions, you may see a speed improvement by increasing threads with -t X, where X is the number of threads.
Options
Most users will want to limit collection to relevant services and regions. Running without any options will attempt to collect all resources from all 16 regular regions.
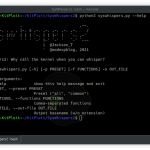
$ aws_recon -h
AWS Recon - AWS Inventory Collector
Usage: aws_recon [options]
-r, --regions [REGIONS] Regions to scan, separated by comma (default: all)
-n, --not-regions [REGIONS] Regions to skip, separated by comma (default: none)
-s, --services [SERVICES] Services to scan, separated by comma (default: all)
-x, --not-services [SERVICES] Services to skip, separated by comma (default: none)
-c, --config [CONFIG] Specify config file for services & regions (e.g. config.yaml)
-o, --output [OUTPUT] Specify output file (default: output.json)
-f, --format [FORMAT] Specify output format (default: aws)
-t, --threads [THREADS] Specify max threads (default: 8, max: 128)
-z, --skip-slow Skip slow operations (default: false)
-j, --stream-output Stream JSON lines to stdout (default: false) -v, --verbose Output client progress and current operation
-d, --debug Output debug with wire trace info
-h, --help Print this help informationOutput
Output is always some form of JSON – either JSON lines or plain JSON. The output is either written to a file (the default), or written to stdout (with -j).
Supported Services & Resources
Current “coverage” by service is listed below. The services without coverage will eventually be added. PRs are certainly welcome. 🙂
AWS Recon aims to collect all resources and metadata that are relevant in determining the security posture of your AWS account(s). However, it does not actually examine the resources for security posture – that is the job of other tools that take the output of AWS Recon as input.
- AdvancedShield
- Athena
- GuardDuty
- Macie
- Systems Manager
- Trusted Advisor
- ACM
- API Gateway
- AutoScaling
- CodePipeline
- CodeBuild
- CloudFormation
- CloudFront
- CloudWatch
- CloudWatch Logs
- CloudTrail
- Config
- DirectoryService
- DirectConnect
- DMS
- DynamoDB
- EC2
- ECR
- ECS
- EFS
- ELB
- EKS
- Elasticsearch
- Firehose
- FMS
- Glacier
- IAM
- KMS
- Kafka
- Kinesis
- Lambda
- Lightsail
- Organizations
- RDS
- Redshift
- Route53
- Route53Domains
- S3
- SageMaker
- SES
- ServiceQuotas
- Shield
- SNS
- SQS
- Transfer
- VPC
- WAF
- WAFv2
- Workspaces
- Xray
Additional Coverage
One of the primary motivations for AWS Recon was to build a tool that is easy to maintain and extend. If you feel like coverage could be improved for a particular service, we would welcome PRs to that effect. Anyone with a moderate familiarity with Ruby will be able to mimic the pattern used by the existing collectors to query a specific service and add the results to the resource collection.
Development
Clone this repository:
$ git clone [email protected]:darkbitio/aws-recon.git
$ cd aws-reconCreate a sticky gemset if using RVM:
$ rvm use 2.6.5@aws_recon_dev --create --ruby-versionRun bin/setup to install dependencies. Then, run rake test to run the tests. You can also run bin/console for an interactive prompt that will allow you to experiment.
To install this gem onto your local machine, run bundle exec rake install. To release a new version, update the version number in version.rb, and then run bundle exec rake release, which will create a git tag for the version, push git commits and tags, and push the .gem file to rubygems.org.
TODO
- Optionally suppress AWS API errors instead of re-raising them
- Package as a gem
- Test coverage with AWS SDK stubbed resources
Kudos
AWS Recon was inspired by the excellent work of the people and teams behind these tools:
- CloudMapper https://github.com/duo-labs/cloudmapper
- Prowler https://github.com/toniblyx/prowler
- CloudSploit https://github.com/cloudsploit/scans
[sc name=”ad-in-article”]

Add Comment