







LeakScraper is an efficient set of tools to process and visualize huge text files containing credentials. These tools are designed to help pentesters/redteamers doing OSINT, credentials gathering and credentials stuffing attacks.

Installation
- First things first : have a working mongodb server.
- Then :
git clone -b mongodb https://github.com/Acceis/leakScraper cd leakScraper sudo ./leakScraper/install.shIt will install a few pip packages and debian packages (python-magic, python3-pymongo and bottle).
Requirements
Linux (debian), python 3.x and a mongodb server.
Usage
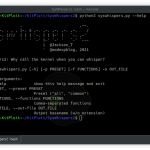
See the wiki
The different tools
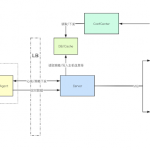
LeakScraper is split into three parts :
- leakStandardizer : A tool to standardize leaks you got from some legit place on the internet. It takes in input a file containing credentials following some weird format, containing non ascii characters or empty lines, lines containing invalid emails or no password. It will produce, with your help (using regular expression), an easily greppable file using the following format :
email:hash:plain(“plain” for “plain text password”). - leakImporter : A tool to import a standardized leak file into a mongodb database. It will take care of extracting data from the file, putting it into a mysql comprehensive format, creating/managing indexes …
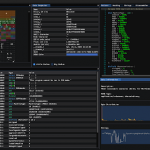
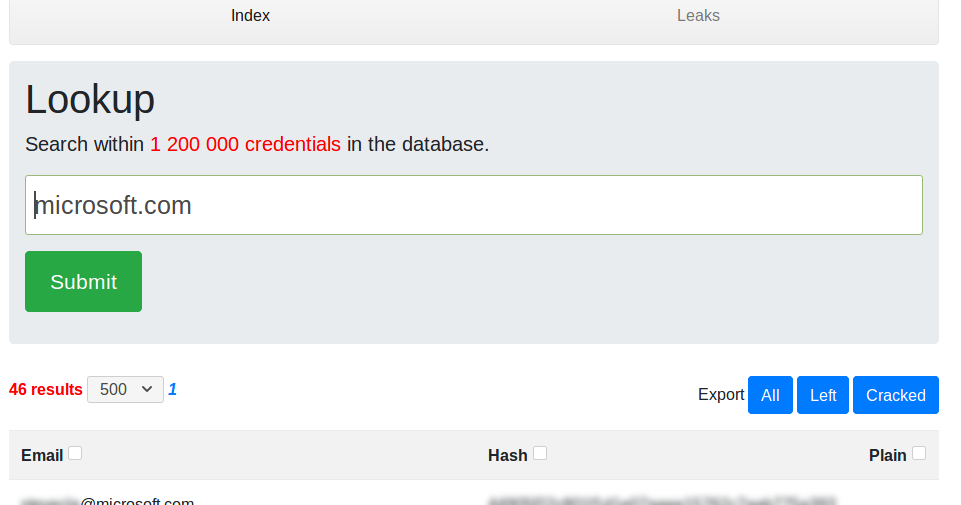
- leakScraper : A tool and an interface to excavate data from the database and display it nicely.
Postulates
- The covered usecase is the following : searching credentials belonging to a specific organization/company/structure. This is done by searching credentials associated to an email belonging to the organization in question. Eg: Searching credentials belonging to microsoft is done by searching credentials associated to accounts registered with an email ending with “@microsoft.com”. It is the only usecase covered and it means a lot in terms of technical choices (database indexes and data representation in general).
- Leaks can weight several gigabytes. It means that each process (standardizing, imports and researches) are using in-place algorithms in terms of memory. You can know beforehand how much memory theses tools will use to process a specific file, and it will never exhaust your computer’s resources (unless you have a very old one).
- Processing huge files and working with a lot of data takes time. It’s important imo to have visual/real-time feedback to know how much time processing/importing a file will take. It’s important to know if you just started a 7 hours long process or a 1,200 years long one.


Add Comment