







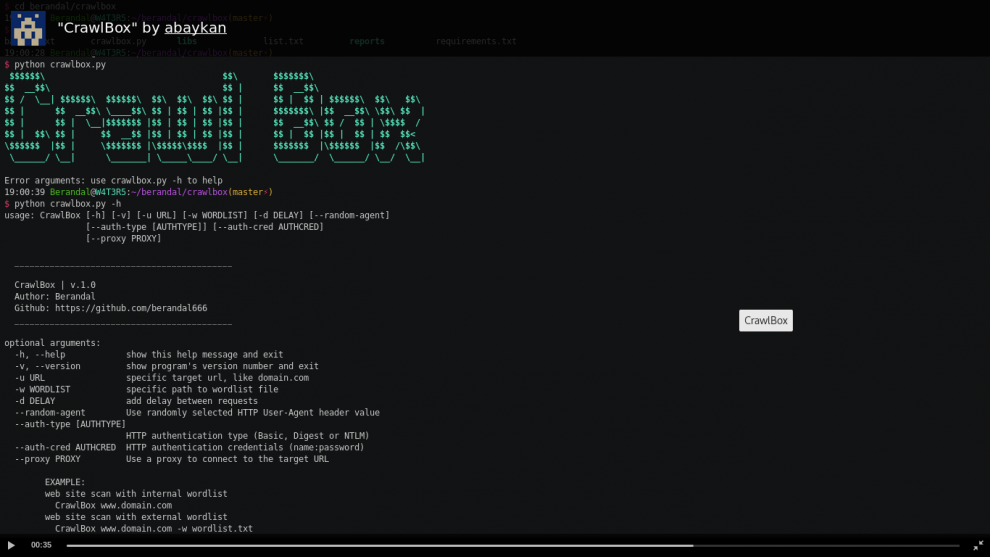
Easy way to brute-force web directory.
Operating Systems Tested:
- MacOSX
- Kali Linux
Usage:
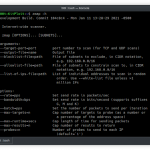
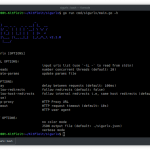
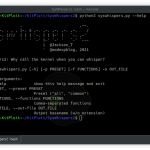
python crawlbox.py [-h] [-v] [-w WORDLIST] urlpositional arguments:
url specific target url, like domain.comoptional arguments:
-h, --help show this help message and exit
-v, --version show program's version number and exit
-w WORDLIST specific path to wordlist file
-d DELAY add delay between requestsExample
web site scan with internal wordlist
python crawlbox.py www.domain.comweb site scan with external wordlist
python crawlbox.py www.domain.com -w wordlist.txtInstall
(as root)
git clone https://github.com/abaykan/crawlbox.git
cd crawlbox/
pip install -r requirements.txt
python crawlbox.py -hnote: tested with python 2.7.6

Add Comment