








[sc name=”ad_1″]
Tested environments: Windows, MAC, linux, and windows subsystem for linux (WSL)
What can SourceWolf do?
- Crawl through responses to find hidden endpoints, either by sending requests, or from the local response files (if any).
- Create a list of javascript variables found in the source
- Extract all the social media links from the websites to identify potentially broken links
- Brute forcing host using a wordlist.
- Get the status codes for a list of URLs / Filtering out the live domains from a list of hosts.
All the features mentioned above execute with great speed.
- SourceWolf uses the Session module from the requests library, which means, it reuses the TCP connection, making it really fast.
- SourceWolf provides you with an option to crawl the responses files locally so that you aren’t sending requests again to an endpoint, whose response you already have a copy of.
- The final endpoints are in a complete form with a host like
https://example.com/api/adminare not as/api/admin. This can come useful, when you are scanning a list of hosts.
Installation
- git clone https://github.com/micha3lb3n/SourceWolf (or) Download the latest release!
- cd SourceWolf/
- pip3 install -r requirements.txt
Usage
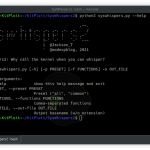
> python3 sourcewolf.py -h
-l LIST, --list LIST List of javascript URLs
-u URL, --url URL Single URL
-t THREADS, --threads THREADS
Number of concurrent threads to use (default 5)
-o OUTPUT_DIR, --output directory-name OUTPUT_DIR
Store URL response text in a directory for further analysis
-s STATUS_CODE_FILE, --store-status-code STATUS_CODE_FILE
Store the status code in a file
-b BRUTE, --brute BRUTE
Brute force URL with FUZZ keyword (--wordlist must also be used along with this)
-w WORDLIST, --wordlist WORDLIST
Wordlist for brute forcing URL
-v, --verbose Verbose mode (displays all the requests that are being sent)
-c CRAWL_OUTPUT, --crawl-output CRAWL_OUTPUT
Output directory to store the crawled output
-d DELAY, --delay DELAY
Delay i n the requests (in seconds)
--timeout TIMEOUT Maximum time to wait for connection timing out (in seconds)
--headers HEADERS Add custom headers (Must be passed in as {'Token': 'YOUR-TOKEN-HERE'}) --> Dictionary format
--cookies COOKIES Add cookies (Must be passed in as {'Cookie': 'YOUR-COOKIE-HERE'}) --> Dictionary format
--only-success Only print 2XX responses
--local LOCAL Directory with local response files to crawl for
--no-colors Remove colors from the output
--update-info Check for the latest version, and update if required
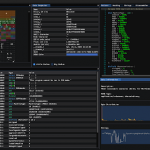
- Crawl response mode:
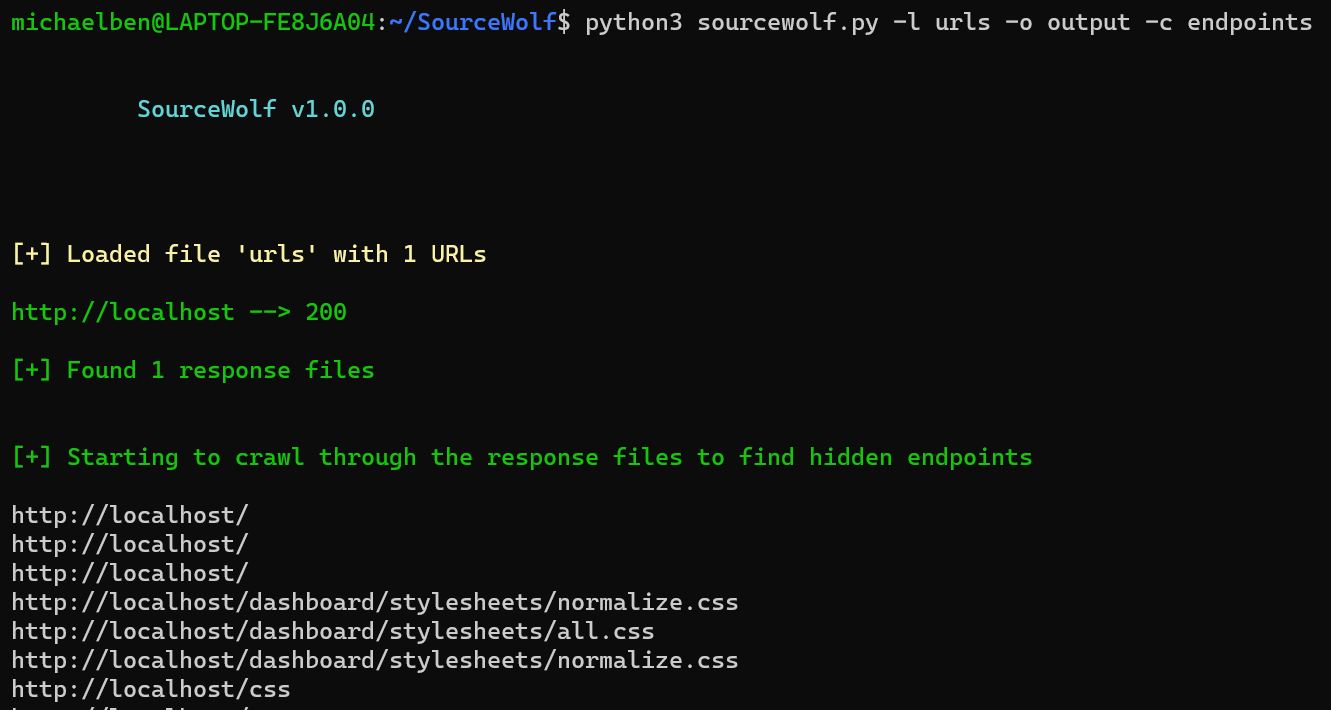
Complete usage:
python3 sourcewolf.py -l domains -o output/ -c crawl_outputdomains is the list of URLs, which you want to crawl in the format:
https://example.com/
https://exisiting.example.com/
https://exisiting.example.com/dashboard
https://example.com/hitmeoutput/ is the directory where the response text files of the input file are stored.
They are stored in the format output/2XX, output/3XX, output/4XX, and output/5XX.
output/2XX stores 2XX status code responses, and so on!
crawl_output specified using the -c flag is used to store the output, inside a directory which SourceWolf produces by crawling the HTTP response files, stored inside the output/ directory (currently only endpoints)
The crawl_output/ directory contains:
endpoints – All the endpoints found
jsvars – All the javascript variables
The directory will have more files, as more modules, and features are integrated into SourceWolf.
For a single URL,
python3 sourcewolf.py -u example.com/api/endpoint -o output/ -c crawl_outputOnly the flag -l is replaced by -u, everything else remains the same.
- Brute force mode
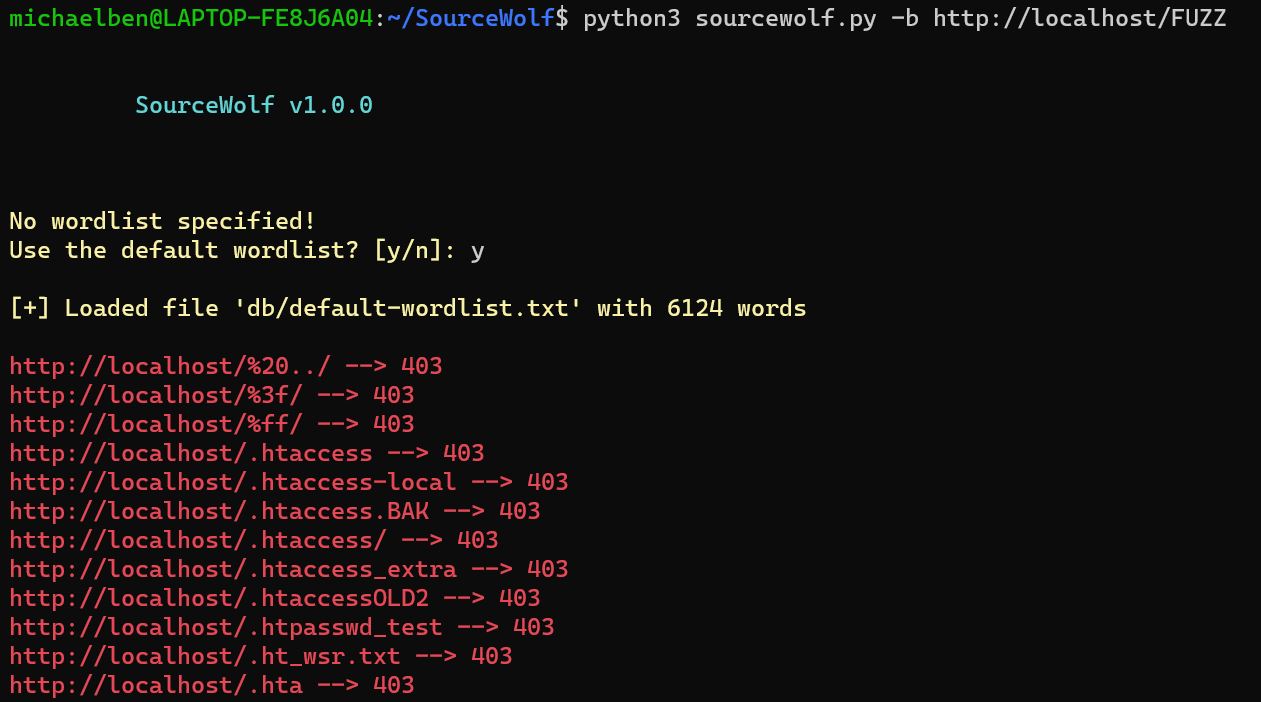
python3 sourcewolf.py -b https://hackerone.com/FUZZ -w /path/to/wordlist -s status-w flag is optional. If not specified, it will use a default wordlist with 6124 words
SourceWolf replace the FUZZ keyword from the -b value with the words from wordlist, and sends the requests. This enables you to brute force get parameter values as well.
-s will store the output in a file called status
- Probing mode
Screenshot not included as the output looks similar to
crawl responsemode.
python3 sourcewolf -l domains -s liveThe domains file can have anything like subdomains, endpoints, js files.
The -s flag write the response to the live file.
Both the brute force and probing mode prints all the status codes except 404 by default. You can customize this behavior to print only
2XXresponses by using the flag--only-success
SourceWolf also makes use of multithreading.
The default number of threads for all modes is 5. You can increase the number of threads using the -t flag.
In addition to the above three modes, there is an option crawl locally, provided you have them locally, and follow sourcewolf compatible naming conventions.
Store all the responses in a directory, say responses/
python3 sourcewolf.py --local responses/This will crawl the local directory, and give you the results.
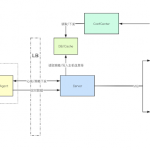
How can this be integrated into your workflow?
|
| SourceWolf
|
| Filter out live subdomains
|
| Store responses and find hidden endpoints / Directory brute forcing
At this point, you will have a lot of endpoints from the target, extracted real time from the web pages at the time of performing the scan.
SourceWolf core purpose is made with a broader vision to crawl through responses not just for discovering hidden endpoints, but also for automating all the tasks which are done by manually searching through the response files.
One such example would be manually searching for any leaked keys in the source.
This core purpose explains the modular way in which the files are written.
To do
- Generate a custom wordlist for a target from the words obtained in the source.
- Automate finding any leaked keys.
Updates
It is possible to update SourceWolf right from the terminal, without you having to clone the repository again.
SourceWolf checks for updates everytime it runs, and notifies the user if there are any updates available along with a summary of it.
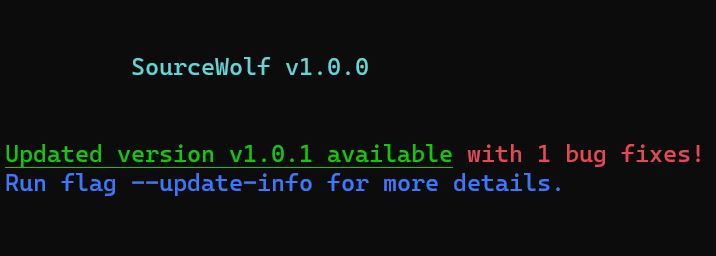
Running
python3 sourcewolf.py --update-infoprovides more details on the update
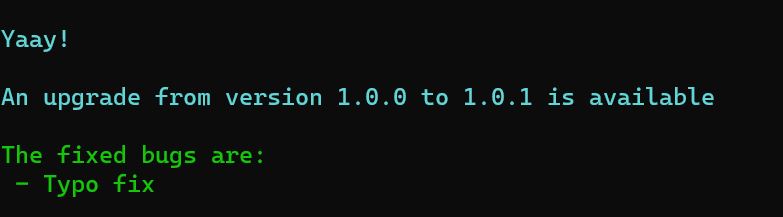
When there are updates available, you must move the update.py file outside of the SourceWolf directory, and run
Warning: This deletes all the files and folders inside your SourceWolf directory
python3 update.py /path/to/SourceWolfThis actually removes the directory, and clones back the repo.
Currently, sourcewolf supports only finding hidden endpoints from the source, but you can expect other features to be integrated in the future.
Where can you contribute?
Contributions are mainly required for integrating more modules, with sourcewolf, though feel free to open a PR even if it’s a typo.
Before sending a pull request, ensure that you are on the latest version.
> Open an issue first if you are going to add a new feature to confirm if it’s required! You must not be wasting time trying to code a new feature which is not required.
Feel free to open any issues you face.
Ensure that you include your operating system, command which was run, and screenshots if possible while opening an issue, which makes it easier for me to reproduce the issue.
You can also request new features, or enhance existing features by opening an issue.
Naming conventions
To crawl the files locally, you must follow some naming conventions. These conventions are in place for SourceWolf to directly identify the host name, and thereby parse all the endpoints, including the relative ones.
Consider an URL https://example.com/api/
- Remove the protocol and the trailing slash (if any) from the URL –>
example.com/api - Replace ‘/’ with ‘@’ –>
example.com@api - Save the response as a txt file with the file name obtained above.
So the file finally looks like [email protected]
Credits
Logo designed by Murugan artworks
[sc name=”ad-in-article”]

Add Comment