








Nameles provides an easy to deploy, scalable IVT detection and filtering solution that is proven to detect at a high level of accuracy ad fraud and other types of invalid traffic such as web scraping.
- Comprehensive Detection
Detects display, video and in-app based ad fraud, web scraping and other forms of invalid traffic from both mobile and desktop sources. - Entropy Method
Entropy measurement is one of the most widely used methods for detecting anomalies in large datasets with many unknowns across a wide range of problems.
- Scalable Architecture
Highly optimized C++ codes run on minimal computing resource and scale to meet the needs of even the largest advertising technology companies.
- Low Operation Cost
Pre-bid filtering of 300,000 QPS traffic stream have the total-cost-of-operation of less than $5,000 per month with below 50ms decision delay. - Permissive Licence
The permissive apache license allows reuse, modification, and reselling to meet the needs of all advertising technology companies. - Built by Experts
Built in close collaboration between the most experienced ad fraud experts, leading adtech innovators, and highly regarded academic researchers.
Detection Capability
While absolute measurement of detection capability is impossible, Nameles is the only detection solution that can be audited by indepedent parties and that is backed by several scientfic papers.
Nameles can detect invalid traffic on:
- mobile and desktop
- display, video, and in-app
Detection Method
Nameles implements a highly scalable entropy measurement using Shannon entropy of the IP addresses a given site is receiving traffic from, and then assigns a normalized score to the site based on its traffic pattern.
Entropy have been used widely in finance, intelligence, and other fields where dealing with vast amounts of data and many unknowns characterize the problem. The use of Shannon entropy has been covered in hundreds of scientific papers. Some argue that Shannon received it from Alan Turing himself, and that it was the method Turing used for cracking the Nazi code.
System Overview
Nameles consist of two separate modules
- the scoring-module
- the data-processing-module
The scoring-module replies to the query messages sent by DSP with the confidence score of the domain and the category in which the domain falls, based on the statistical thresholds of outlierness. In addition, the scoring-module forwards the messages to the data-processing-module for updating the scores at the end of the day. Modules communicate using zeromq.
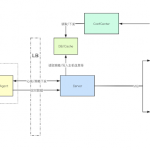
Figure 1: An example deployment with a DSP

Figure 1 presents a high level representation of Nameles functional blocks. Moreover, the figure shows how Nameles could be integrated in the programmatic ad delivery chain as an auxiliary service for the DSPs. The only difference with respect to the current operation of a DSP would be that, as part of the pre-bid phase, the DSP makes a request to Nameles to provide a Confidence Score per bid request. To this end, the DSP sends a scoring request to Nameles (step 2 in Figure 3). The scoring request includes the following fields: bid request id (mapping Nameles result to the corresponding bid request), IP address of the device associated with the bid event and the domain offering the ad space. This information is included in the bid requests as defined in the openRTB protocol standard. The scoring request is delivered to two independent modules of Nameles: the Scoring module and the Filtering module.
Scoring Module
The scoring-module runs several worker threads that pull the queries from the DSP end and push the reply messages. The workers perform a single lookup in a shared hash table for each message. Therefore, the host running the scoring-module module requires minimal memory and drive. We recommend setting a worker per CPU and running latency tests with your expected throughtput load in order to dimensionate an appropriate number of processors for the host. Note that you can run several scoring modules in your system communicating with the same data processing module.
Data Processing Module
The data-processing-module performs precomputations with the stream of data received from the scoring module. The data is periodically serialized to a PostgreSQL database. The scores are computed at the end of each day. The host of this module would benefit from having a high amount of RAM and a certain number of processors in order to reduce the score computation times. We recommend at least 64GB of RAM and 4 cores.
Scalability
In the case of a DSP a response to a given bid request has to be received by the Ad Exchange within 100 ms. Hence, the delay introduced by Nameles is limited to few ms in order to minimize the impact in the overall bidding process delay. This ensures that also in Exchange use, the strict requirements for avoiding delays on publisher websites are avoided.
Figure 2: Stress-testing results with Nameles using real data

Figure 2 the performance of Nameles once deployed. The x-axis shows the different tested scoring request rates. The left y-axis and right y-axis show the 95-percentile filtering delay and 95-percentile memory consumption for the different scoring request rates (QPS). The line in the figure represents the average of 95-percentile values across the 5 experiments whereas the lighter color area shows the max and min 95-percentile values.
Before Deployment
System Requirements
You have the option of setting up Nameles on a single machine, or 3 separate machines. For a production system, we recommend:
Operating System
Nameles have been built and tested on Ubuntu / Debian systems.
Single Machine
- 4 cpu cores
- 64GB of RAM
Multi Machine
- scoring module
- 2 cpu cores
- 4GB of RAM
- data processing module
- 4 cpu cores
- 64GB of RAM
- dsp emulator module
- 4 cpu cores
- 8GB of RAM
Depedencies
Depencies will be taken care by the setup script, so you should not have to worry about anything more than running ./setup as shown in the section 2.1. and 2.2. depending on your system configuration. The main depencies are:
- docker-ce
- psql
Install Nameles
You can install Nameless on a single machine or a cluster of multiple machines following the instructions on section 2.1 below. There are two options:
- single configuration deployment
- multiple configuration deployment
If you install Nameles on a multiple machine docker cluster/swarm, then you have two options: a) where you let docker allocate resources per service b) where you allocate reseources yourself.
Installation with Setup Script
For running Nameles on a single server on an Ubuntu or Debian system:
# download the setup script wget https://raw.githubusercontent.com/Nameles-Org/Nameles/master/setup # change the permissions chmod +x setup # run the setup script ./setup
Add Comment