







[sc name=”ad_1″]
Nautilus is a coverage guided, grammar based fuzzer. You can use it to improve your test coverage and find more bugs. By specifying the grammar of semi valid inputs, Nautilus is able to perform complex mutation and to uncover more interesting test cases. Many of the ideas behind this fuzzer are documented in a Paper published at NDSS 2019.

Version 2.0 has added many improvements to this early prototype and is now 100% compatible with AFL++. Besides general usability improvements, Version 2.0 includes lots of shiny new features:
- Support for AFL-Qemu mode
- Support for grammars specified in python
- Support for non-context free grammars using python scripts to generate inputs from the structure
- Support for specifying binary protocols/formats
- Support for specifying regex based terminals that aren’t part of the directed mutations
- Better ability to avoid generating the same very short inputs over and over
- Massive cleanup of the code base
- Helpful error output on invalid grammars
- Fixed a bug in the the timeout code that occasionally deadlocked the fuzzer
How Does Nautilus Work?
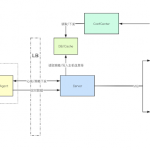
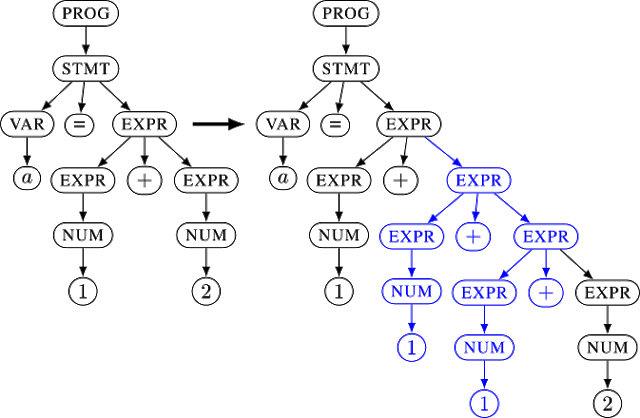
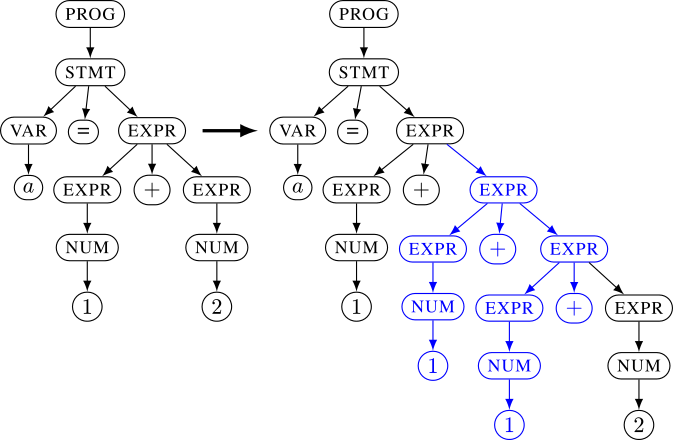
You specify a grammar using rules such as EXPR -> EXPR + EXPR or EXPR -> NUM and NUM -> 1. From these rules, the fuzzer constructs a tree. This internal representation allows to apply much more complex mutations than raw bytes. This tree is then turned into a real input for the target application. In normal Context Free Grammars, this process is straightforward: all leaves are concatenated. The left tree in the example below would unparse to the input a=1+2 and the right one to a=1+1+1+2. To increase the expressiveness of your grammars, using Nautilus you are able to provide python functions for the unparsing process to allow much more complex specifications.
Setup
# checkout the git
git clone '[email protected]:nautilus-fuzz/nautilus.git'
cd nautilus
/path/to/AFLplusplus/afl-clang-fast test.c -o test #afl-clang-fast as provided by AFL
# all arguments can also be set using the config.ron file
cargo run --release -- -g grammars/grammar_py_example.py -o /tmp/workdir -- ./test @@
# or if you want to use QEMU mode:
cargo run /path/to/AFLplusplus/afl-qemu-trace -- ./test_bin @@
Examples
Here, we use python to generate a grammar for valid xml-like inputs. Notice the use of a script rule to ensure the the opening and closing tags match.
#ctx.rule(NONTERM: string, RHS: string|bytes) adds a rule NONTERM->RHS. We can use {NONTERM} in the RHS to request a recursion.
ctx.rule("START","<document>{XML_CONTENT}</document>")
ctx.rule("XML_CONTENT","{XML}{XML_CONTENT}")
ctx.rule("XML_CONTENT","")
#ctx.script(NONTERM:string, RHS: [string]], func) adds a rule NONTERM->func(*RHS).
# In contrast to normal `rule`, RHS is an array of nonterminals.
# It's up to the function to combine the values returned for the NONTERMINALS with any fixed content used.
ctx.script("XML",["TAG","ATTR","XML_CONTENT"], lambda tag,attr,body: b"<%s %s>%s</%s>"%(tag,attr,body,tag) )
ctx.rule("ATTR","foo=bar")
ctx.rule("TAG","some_tag")
ctx.rule("TAG","other_tag")#sometimes we don’t want to explore the set of possible inputs in more detail. For example, if we fuzz a script
#interpreter, we don’t want to spend time on fuzzing all different variable names. In such cases we can use Regex
#terminals. Regex terminals are only mutated during generation, but not during normal mutation stages, saving a lot of time.
#The fuzzer still explores different values for the regex, but it won’t be able to learn interesting values incrementally.
#Use this when incremantal exploration would most likely waste time.
ctx.regex("TAG","[a-z]+")
>To test your grammars you can use the generator:
$ cargo run --bin generator -- -g grammars/grammar_py_exmaple.py -t 100
<document><some_tag foo=bar><other_tag foo=bar><other_tag foo=bar><some_tag foo=bar></some_tag></other_tag><some_tag foo=bar><other_tag foo=bar></other_tag></some_tag><other_tag foo=bar></other_tag><some_tag foo=bar></some_tag></other_tag><other_tag foo=bar></other_tag><some_tag foo=bar></some_tag></some_tag></document>You can also use Nautilus in combination with AFL. Simply point AFL -o to the same workdir, and AFL will synchronize with Nautilus. Note that this is one way. AFL imports Nautilus inputs, but not the other way around.
#Terminal/Screen 1
./afl-fuzz -Safl -i /tmp/seeds -o /tmp/workdir/ ./test @@#Terminal/Screen 2
cargo run --release -- -o /tmp/workdir -- ./test @@
Trophies
- https://github.com/Microsoft/ChakraCore/issues/5503
- https://github.com/mruby/mruby/issues/3995 (CVE-2018-10191)
- https://github.com/mruby/mruby/issues/4001 (CVE-2018-10199)
- https://github.com/mruby/mruby/issues/4038 (CVE-2018-12248)
- https://github.com/mruby/mruby/issues/4027 (CVE-2018-11743)
- https://github.com/mruby/mruby/issues/4036 (CVE-2018-12247)
- https://github.com/mruby/mruby/issues/4037 (CVE-2018-12249)
- https://bugs.php.net/bug.php?id=76410
- https://bugs.php.net/bug.php?id=76244
[sc name=”ad-in-article”]

Add Comment