








Across the Internet, hundreds of thousands of sites rely on Google’s reCaptcha system for defense against bots (in fact, Devpost uses reCaptcha when creating a new account). After a Google research team demonstrated a near complete defeat of the text reCaptcha in 2012, the reCaptcha system evolved to rely on audio and image challenges, historically more difficult challenges for automated systems to solve. Google has continually iterated on its design, releasing a newer and more powerful version as recently as just this year. Successfully demonstrating a defeat of this captcha system spells significant vulnerability for hundreds of thousands of popular sites.
What it does
unCaptcha system has attack capabilities written for the audio captcha. Using browser automation software, we can interact with the target website and engage with the captcha, parsing out the necessary elements to begin the attack. We rely primarily on the audio captcha attack – by properly identifying spoken numbers, we can pass the reCaptcha programmatically and fool the site into thinking our bot is a human. Specifically, unCaptcha targets the popular site Reddit by going through the motions of creating a new user, although unCaptcha stops before creating the user to mitigate the impact on Reddit.
Background
Google’s reCaptcha system uses an advanced risk analysis system to determine programmatically how likely a given user is to be a human or a bot. It takes into account your cookies (and by extension, your interaction with other Google services), the speed at which challenges are solved, mouse movements, and (obviously) how successfully you solve the given task. As the system gets increasingly suspicious, it delivers increasingly difficult challenges, and requires the user to solve more of them. Researchers have already identified minor weaknesses with the reCaptcha system – 9 days of legitimate (ish) interaction with Google’s services is usually enough to lower the system’s suspicion level significantly.
How it works
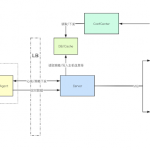
The format of the audio captcha is a varied-length series of numbers spaced out read aloud at varied speeds, pitches, and accents through background noise. To attack this captcha, the audio payload is identified on the page, downloaded, and automatically split by locations of speech.
From there, each number audio bit is uploaded to 6 different free, online audio transcription services (IBM, Google Cloud, Google Speech Recognition, Sphinx, Wit-AI, Bing Speech Recognition), and these results are collected. We ensemble the results from each of these to probabilistically enumerate the most likely string of numbers with a predetermined heuristic. These numbers are then organically typed into the captcha, and the captcha is completed. From testing, we have seen 92%+ accuracy in individual number identification, and 85%+ accuracy in defeating the audio captcha in its entirety.

Briefly, unCaptcha works in the following steps:
- Download the audio captcha
- Segment the audio into individual digit audio clips
- Upload each segment to multiple online speech-to-text services
- Convert these services’ responses to digits:
- Exact homophones: If it is “one” “two”, etc., then guess that number
- Near homophones: If it sounds like a digit, like “true” sounds like “two”, then guess what it sounds like
- Ensemble the multiple services together by taking a weighted vote based on confidence
- And finally upload the answer
Installation
First, install python dependencies:
$ pip install -r requirements.txt
Make sure you also have sox, ffmpeg, and selenium installed!
$ apt-get install sox ffmpeg selenium
Then, to kick off the PoC:
$ python main.py --audio --reddit
This opens reddit.com, interacts with the page to go to account signup, generates a fake username, email, password, and then attacks the audio captcha. Once the captcha is completed (whether it passed or not), the browser exits.


Add Comment